

![[2025 Guide] How to Extract Images from PDF in Python without Effort](https://cdn.hashnode.com/res/hashnode/image/upload/v1726825040796/254f9385-c8ef-4dd6-a37d-55e4d1279fdf.png?w=1600&h=840&fit=crop&crop=entropy&auto=compress,format&format=webp)
PDF has long been a popular document format due to its stability and compatibility across different systems. These files often contain both text and images. Whether you're citing content for a report or saving images for later use, extracting images from a PDF can be tricky, especially since it usually requires Adobe Acrobat.
But don’t worry, this article will guide you through using Python to extract images from PDF documents. With these steps, you’ll be able to tackle the task easily, saving both time and effort.
Prepare for Tasks
To complete this task, we will need Spire.PDF for Python. It is a professional PDF component that allows users to create, edit, convert, and compress PDF documents in Python, etc. This tool offers various classes and methods to help developers deal with PDF documents, including extracting images from PDF documents.
You can install Spire.PDF for Python from PyPI using the following pip command:
pip install Spire.Pdf
If you already have Spire.PDF for Python installed and would like to upgrade to the latest version, use the following pip command:
pip install --upgrade Spire.Pdf
Python: How to Extract Images from a PDF Page
Now that you have fully prepared for the task and have installed Spire.PDF, let’s get down to the point of how to extract images from PDF pages. Although extracting all the images from a PDF at once can be efficient, you may often need to extract images on a page-by-page basis. For example, when you only require the content from a specific chapter.
In the following section, we will explain how to use Python to extract images from individual PDF pages, offering a more focused and customizable approach.
Steps to extract images from a PDF page:
Import essential modules.
Create an object of PdfDocument class, and use the PdfDocument.LoadFromFile() method to read a PDF file.
Instantiate a PdfImageHelper class.
Get a specific PDF page using the PdfDocument().Pages.get_Item() method.
Use the imageHelper.GetImagesInfo() method to get the image information of a certain page.
Iterate through image information and save extracted images by calling the imageInfo[].Image.Save()method.
Release resources.
Below is the code example of extracting images from the last PDF page:
from spire.pdf import PdfDocument, PdfImageHelper
# Create a PdfDocument instance
pdf = PdfDocument()
# Load a PDF file from the file
pdf.LoadFromFile("/sample.pdf")
# Create a PdfImageHelper instance
imageHelper = PdfImageHelper()
# Get the last page of the PDF document
page = pdf.Pages.get_Item(pdf.Pages.Count - 1)
# Get the image information of the page
imageInfo = imageHelper.GetImagesInfo(page)
# Iterate through the image information
for i in range(0, len(imageInfo)):
# Save images to the disk
imageInfo[i].Image.Save("/PDFImages/Image" + str(i) + ".png")
# Release resources
pdf.Dispose()

Python: Extract Images from a PDF Document
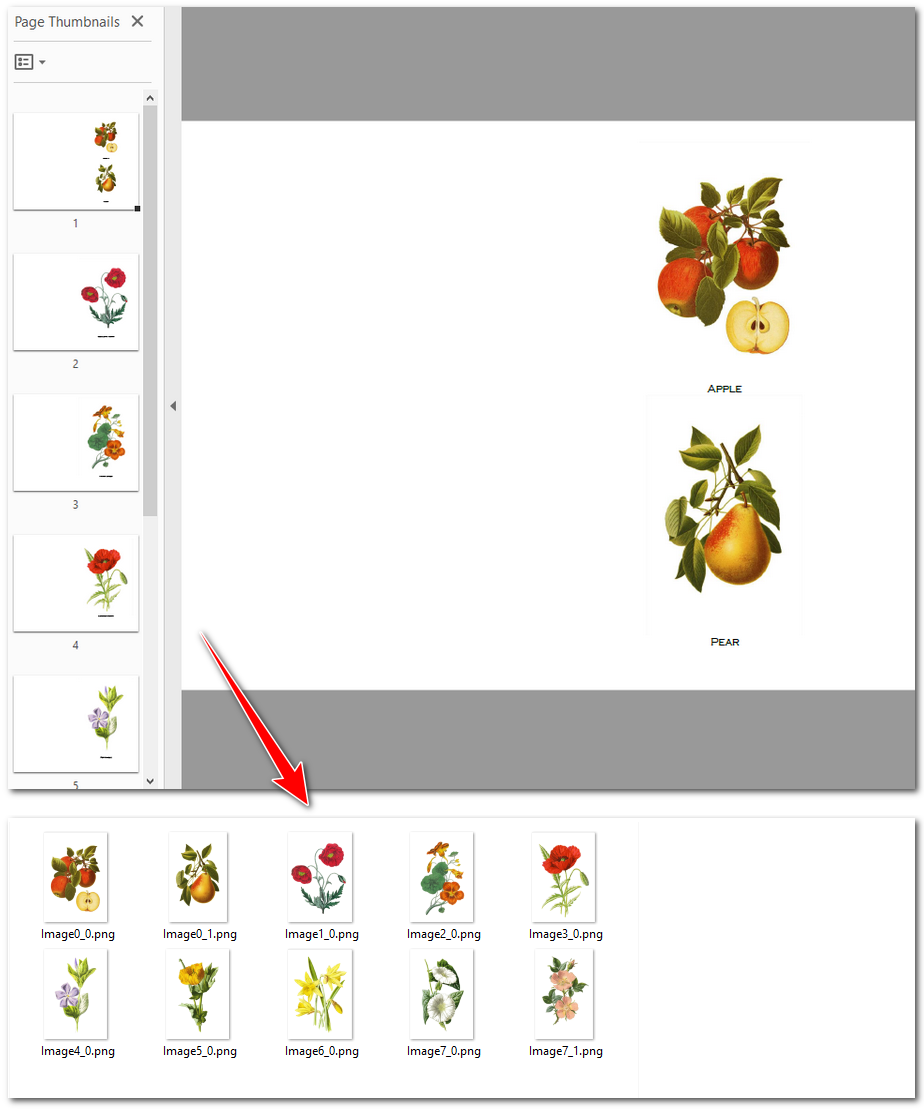
As we have learned how to extract pictures from a PDF page, time to check out how to do it in an entire PDF document. Extracting photos from a PDF document is a common task. Spire.PDF allows you to retrieve all images from an entire PDF file easily and fast, handling PDF documents seamlessly. Retrieving pictures from a PDF document is one step more compared to doing that from a page, that is, looping through each page of the PDF file before traversing the image information. Here’s how.
Steps to extract images from a PDF file:
Import essential modules.
Create a PdfDocument object and call the PdfDocument.LoadFromFile() method to load a PDF file.
Create an object of the PdfImageHelper class.
Iterate through pages of the PDF document and get the current page using the PdfDocument().Pages.get_Item() method.
Get image information of the page with the imageHelper.GetImagesInfo() method.
Using the imageInfo[].Image.Save() method to store images on this page and name them in order.
Release resources.
Here is the code example of how to extract all images from PDF documents:
from spire.pdf import PdfDocument, PdfImageHelper
# Create a PdfDocument instance
pdf = PdfDocument()
# Load a PDF document from the file
pdf.LoadFromFile("E:/Administrator/Python1/input/set.pdf")
# Create a PdfImageHelper instance
imageHelper = PdfImageHelper()
# Iterate through the pages in the document
for i in range(0, pdf.Pages.Count):
# Get the current page
page = pdf.Pages.get_Item(i)
# Get the image information of the page
imageInfo = imageHelper.GetImagesInfo(page)
# Iterate through the image information items
for j in range(0, len(imageInfo)):
# Save the current image to the file
imageInfo[j].Image.Save(f"E:/Administrator/Python1/output/AllImages/Image{i}_{j}.png")
# Release resources
pdf.Close()
The Bottom Line
This guide focuses on how to extract images from PDF documents in Python. You can learn to retrieve pictures from a PDF page and extract all images from a PDF file. Each section contains detailed instructions and a code example. After learning this article, you can deal with PDF documents automatically with high efficiency!