![How to Split Word Documents in Python Like a Pro [Advanced Guide]](https://cdn.hashnode.com/res/hashnode/image/upload/v1736132571350/f508eab9-a6a4-4257-9b97-05cdc5e63c87.png?w=1600&h=840&fit=crop&crop=entropy&auto=compress,format&format=webp)


Have you ever found yourself facing a lengthy Word document, but you only need a specific section? Perhaps you want to print a particular chapter or page, or maybe you're overwhelmed by a long document and wish to break it down into smaller parts. Splitting a Word document is the best solution—it allows you to focus on just the parts you need while keeping the original document intact.
Although you could manually perform this task, automating the process with programming can save you a lot of time and effort. In this article, we'll show you how to split Word documents using Python, including splitting by page numbers, headings, and sections, helping you quickly meet your needs.
Python Library to Split Word Documents
Speaking of spliting Word documents using Python, you may want to directly use a Python editor like VS Code, but third-party libraries will make it much easier because they often contain rich APIs. Among Spire.Doc for Python, Aspose.Words for Python via .NET, and python-docx of PyPI, Spire.Doc (short for Spire.Doc for Python) stands out for its easy-to-understand APIs, and timely technical support. For that, in this guide, I will use it as an example to demonstrate Word file splitting.
How to Split Word Documents by Page Breaks
Let’s start with the most common requirement, spliting a Word document by page breaks. This approach is particularly useful when you need to extract content based on specific pages or when each page represents a distinct section. In this section, I‘ll guide you through the process of splitting Word documents by page breaks using Python, ensuring precision and efficiency.
Steps to split Word documents by page breaks:
Create an object of the Document class, and load the source file using the Document.LoadFromFile() method.
Create a new Word document and add a section to it.
Iterate through all sections and body child objects, and check if they are paragraphs or tables.
If it is a table, add it to the new document using the Section.Body.ChildObjects.Add() method.
If it is a paragraph, clone it to the new Word document and loop through child objects of paragraphs, then check if they are page breaks. If yes, get its index using Paragraph.ChildObjects.IndexOf() method and remove it using the ChildObjects.RemoveAt() method.
Save the modified Word documents as multiple individual files with the Document.SaveToFile() method.
Here is the code example of spliting a Word document by page breaks:
from spire.doc import *
from spire.doc.common import *
# Create an instance of Document
original = Document()
# Load a Word document
original.LoadFromFile("/AI-Generated Art.docx")
# Create a new Word document and add a section to it
newWord = Document()
section = newWord.AddSection()
original.CloneDefaultStyleTo(newWord)
original.CloneThemesTo(newWord)
original.CloneCompatibilityTo(newWord)
index = 0
# Iterate through all sections of the original document
for m in range(original.Sections.Count):
sec = original.Sections.get_Item(m)
# Iterate through all body child objects of each section
for k in range(sec.Body.ChildObjects.Count):
obj = sec.Body.ChildObjects.get_Item(k)
if isinstance(obj, Paragraph):
para = obj if isinstance(obj, Paragraph) else None
sec.CloneSectionPropertiesTo(section)
# Add paragraph object in original section into section of new document
section.Body.ChildObjects.Add(para.Clone())
for j in range(para.ChildObjects.Count):
parobj = para.ChildObjects.get_Item(j)
if isinstance(parobj, Break) and ( parobj if isinstance(parobj, Break) else None).BreakType == BreakType.PageBreak:
# Get the index of page break in paragraph
i = para.ChildObjects.IndexOf(parobj)
# Remove the page break from its paragraph
section.Body.LastParagraph.ChildObjects.RemoveAt(i)
# Save the new document
resultF = outputFolder
resultF += "SplitByPageBreak-{0}.docx".format(index)
newWord.SaveToFile(resultF, FileFormat.Docx)
index += 1
# Create a new document and add a section
newWord = Document()
section = newWord.AddSection()
original.CloneDefaultStyleTo(newWord)
original.CloneThemesTo(newWord)
original.CloneCompatibilityTo(newWord)
sec.CloneSectionPropertiesTo(section)
# Add paragraph object in original section into section of new document
section.Body.ChildObjects.Add(para.Clone())
if section.Paragraphs[0].ChildObjects.Count == 0:
# Remove the first blank paragraph
section.Body.ChildObjects.RemoveAt(0)
else:
# Remove the child objects before the page break
while i >= 0:
section.Paragraphs[0].ChildObjects.RemoveAt(i)
i -= 1
if isinstance(obj, Table):
# Add table object in original section into section of new document
section.Body.ChildObjects.Add(obj.Clone())
# Save the document
result = f"/SplitDocument/SplitByPageBreak-{index}.docx"
newWord.SaveToFile(result, FileFormat.Docx2013)
newWord.Close()
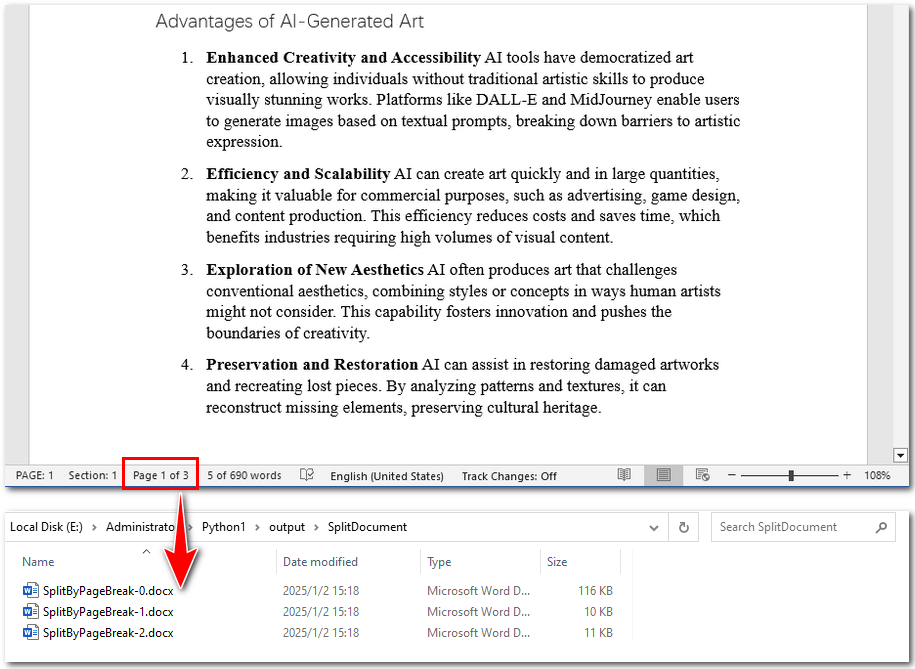
How to Split Word Documents by Headings
Sometimes, splitting a Word document by headings is the most logical choice, as the text under each heading typically relates to a specific topic or section. This method is ideal for creating separate documents by chapters, making it easier to organize, share, or process the content systematically.
Steps to split Word documents by headings
Create an instance of the Document class, and use the Document.LoadFromFile() method to read a Word file.
Create a new Word document and add a section to it.
Loop through all sections and all child objects of each section, check if they are paragraphs. If they are, keep on checking if they are Heading 1 (or Heading 2 and so on).
- If yes, clone them to the new Word document using the Section.Body.ChildObjects.Add() method.
Save the split Word files through the Document.SaveToFile() method.
Below is the code example of splitting a Word document by the first-level headings:
from spire.doc import *
from spire.doc.common import *
# Create a Document instance
document = Document()
# Load the source document
document.LoadFromFile("/AI-Generated Art.docx")
# Initialize variables
new_documents = []
new_document = None
new_section = None
is_inside_heading = False
# Iterate through all sections in the source document
for sec_index in range(document.Sections.Count):
# Access the current section
section = document.Sections[sec_index]
# Iterate through all objects in the current section
for obj_index in range(section.Body.ChildObjects.Count):
# Access the current object
obj = section.Body.ChildObjects[obj_index]
# Check if the current object is a paragraph
if isinstance(obj, Paragraph):
para = obj
# Check if the paragraph style is "Heading1"
if para.StyleName == "Heading1":
# Add the document to the list if it exists
if new_document is not None:
new_documents.append(new_document)
# Create a new document
new_document = Document()
# Add a new section to the new document
new_section = new_document.AddSection()
# Copy section settings
section.CloneSectionPropertiesTo(new_section)
# Copy the paragraph to the new section of the new document
new_section.Body.ChildObjects.Add(para.Clone())
# Set the is_inside_heading flag to True
is_inside_heading = True
else:
# Always copy the content if we are inside a heading-based split
if is_inside_heading:
new_section.Body.ChildObjects.Add(para.Clone())
else:
# Copy non-paragraph objects to the new section if inside heading
if is_inside_heading:
new_section.Body.ChildObjects.Add(obj.Clone())
# Add the last document to the list if it exists
if new_document is not None:
new_documents.append(new_document)
# Iterate through all documents in the list
for i, doc in enumerate(new_documents):
# Copy themes and styles from the source document to ensure consistency
document.CloneThemesTo(doc)
document.CloneDefaultStyleTo(doc)
# Save the document to a separate file
output_file = f"/SplitbyHeading{i + 1}.docx"
doc.SaveToFile(output_file, FileFormat.Docx2016)
How to Split Word Documents by Section Breaks
In this final section, we’ll explore how to split a Word document by section breaks. Word documents often use sections to separate content with different headers, footers, or page orientations. To split a document by sections, you can leverage the Document.Sections.get_Item() and Document.Sections.Add() methods. Below, we’ll walk through the detailed steps to accomplish this.
Steps to split Word documents by section breaks:
Instantiate a Document object, and load a Word document from files through the Document.LoadFromFile() method.
Create a new Word document.
Iterate through all sections and get the current section using the Document.Sections.get_Item() method.
- Add the section to the new document by calling the Document.Sections.Add() method.
Save the new document through the Document.SaveToFile() method.
Here is the code example of splitting a Word file based on sections:
from spire.doc import *
from spire.doc.common import *
# Create an instance of Document class
document = Document()
# Load a Word document
document.LoadFromFile("/AI-Generated Art.docx")
# Iterate through all sections
for i in range(document.Sections.Count):
section = document.Sections.get_Item(i)
result = "/SplitDocument/" + "SplitBySectionBreak_{0}.docx".format(i+1)
# Create a new Word document
newWord = Document()
# Add the section to the new document
newWord.Sections.Add(section.Clone())
#Save the new document
newWord.SaveToFile(result)
newWord.Close()

The Conclusion
In today’s post, we’ve covered how to split Word documents using Python, including step-by-step guides for splitting by page breaks, headings, and section breaks, complete with code examples. By the end of this guide, you’ll see just how simple and efficient it is to split Word files with Python!